Back
Blog
Insights
Intent Divergence, Formalised: EDAMAME's Foundational Research with CNRS Is Now Public

Frank Lyonnet
Today our research paper is public. “Runtime Security for Agentic Systems: A Practical Two-Plane Approach for OpenClaw-Class Agents” — joint work by EDAMAME with the LISTIC laboratory (CNRS) — is now available open-access on HAL, France's national open-research archive. We presented it in June at the PEPR IA Days 2026 in Rennes (22–24 June), the annual gathering of France's national AI research programme under France 2030. This is the science underneath EDAMAME's runtime verification, and we want to explain the idea at its centre: intent divergence.
What intent divergence is
Every security question about an AI agent eventually collapses into one: is the agent doing what it was asked to do? An agent declares an intent — a plan, a tool to call, a reason. Then the machine does something. Intent divergence is the distance between the two: what the agent said it would do, against what actually happened on the host. When that distance grows across a session — because a prompt injection, a poisoned tool, or plain compounding error has quietly redirected the agent — the effective goal slides away from the one you gave it. That is goal drift, and it is the failure mode that matters most, because it does not look like an attack while it is happening.
The hard part is that you cannot answer the question from inside the agent. A misdirected or compromised agent will narrate a perfectly reasonable account of itself; the log it writes is the log it chooses to write. The only account you can actually trust is the one the agent does not control — what the operating system observed: the processes it spawned, the files it opened, the sockets it created, the credentials it touched. That is the ground truth, and it lives outside the agent, where a hijacked agent cannot edit it.
Measuring it honestly
Supply-chain scanning and configuration hardening are necessary, but they are static: they check a package before it runs, and the settings before a session starts. Intent divergence only shows up in what the agent does next. In the recent incidents we studied, the static pre-checks passed — the failure was in the runtime action.
The paper's contribution is architectural, not a claim of universal prevention. It sets out a way to measure intent divergence by correlating two independent accounts of the same agent: what the agent said it was doing, read from its own session, and what the machine actually did, observed from outside the agent at the level of the operating system. The two are brought into one observer-owned correlation window and evaluated against process-attributed host telemetry and model-independent guardrails — so the verdict does not depend on trusting the model that is under suspicion in the first place.
This draws on a well-established discipline — the formal verifiability of autonomous software systems — deciding, on evidence, whether a system's behaviour matches its declared purpose. It is the academic backbone under a number every EDAMAME user already sees: the runtime-verification divergence score, the distance between what a coding agent — Cursor, Claude Code, Codex, OpenClaw — declared and what its host actually did, on an evidence trail you can hand to an auditor.

The runtime-verification divergence score in EDAMAME Security (Alignment / Advanced view): declared agent intent correlated against what the host actually did, scored on an evidence trail. See the AI feature documentation.
What the paper shows — and what it doesn't
On a live, reproducible benchmark — 50 versioned scenario contracts run against an instrumented machine, 468 valid runs across 10 seeds, every verdict tied to recorded host telemetry anyone can replay — the correlation loop reached precision of 1.000 (95% CI [0.988, 1.000]), meaning zero false positives across the benign scenarios, and recall of 0.911 (95% CI [0.876, 0.937]), with a median detection latency of 51.6 seconds (p95 66.9s). Those are early-warning numbers on a narrow, reproducible slice — not a claim of end-to-end coverage — and we report them with confidence intervals precisely so they can be read for what they are.
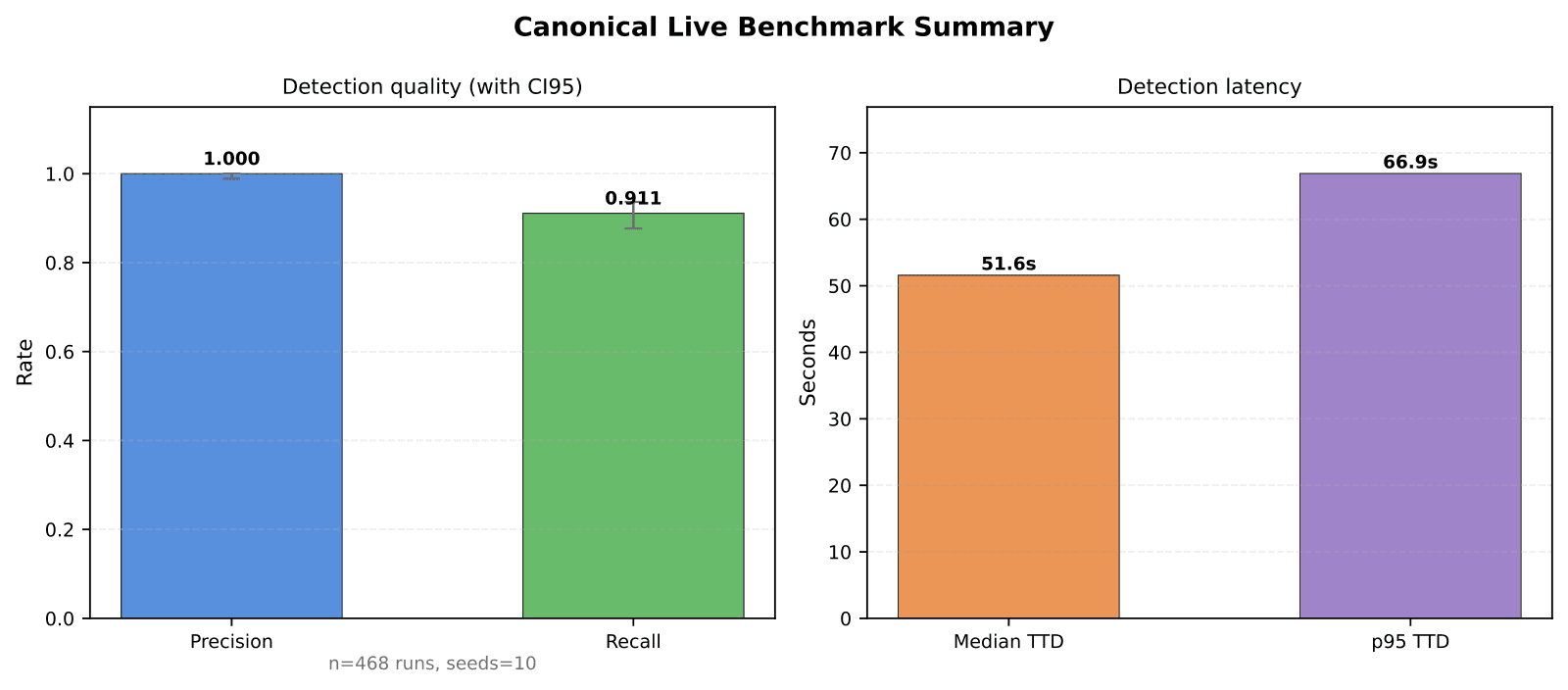
Live benchmark summary from the paper: detection quality (precision 1.000, recall 0.911, with 95% confidence intervals) and detection latency (median 51.6s, p95 66.9s), across 468 valid runs and 10 seeds.
We are just as explicit about the limits, in print and here. The approach is reactive: it detects divergence as it unfolds, within tens of seconds, rather than preventing the first action. And it does not catch everything. The hardest case — the one we tag in the paper as a designed miss — is living off the land: an agent that stays entirely within permitted process-and-destination pairs, doing only allowed things for a forbidden purpose. No behavioural layer catches 100% of that, and we say so plainly. Runtime verification is an early-warning and evidence layer that raises the cost and shrinks the dwell time of an attack; it works alongside preventive controls — identity, sandboxing, egress policy, and your agent's own guardrails — not instead of them.
Foundational work, done with CNRS — and deepening
We want to be precise about what this collaboration is, because the word gets used loosely. It is not a logo on a slide: the paper is co-authored with the LISTIC laboratory at the University of Savoie Mont Blanc (CNRS), pairing formal-methods research with our host-level engineering. That is what “foundational” means here — intent divergence is a research result, and the product is one implementation of it.
It also sits in a specific place on the national map. PEPR IA is France's priority research programme for artificial intelligence — part of the France 2030 investment plan, €73 million over six years, overseen by the CEA, CNRS, and Inria and operated by the ANR. It is organised around three pillars, and one of them is Trustworthy AI, defined to include “the integration of formal methods for the specification, the learning and the validation of AI models.” Intent divergence is precisely that — a formal-methods lens on whether an autonomous agent's behaviour matches its declared purpose. Our work is not adjacent to the national trustworthy-AI agenda; it is inside it.
And we intend to deepen it. The paper is a first, reproducible snapshot; the roadmap runs toward broader agent coverage, harder adversarial benchmarks, and tightening the formal guarantees around the divergence signal. Presenting the joint EDAMAME and LISTIC work at the PEPR IA Days — in front of France's national AI research community — is exactly the right venue to carry that collaboration forward. As a French Deep Tech company and a member of France DeepTech, EDAMAME is built research-first: the science is not marketing dressing on the product, it is the load-bearing wall.
Read the work
The paper, open-access on HAL: Runtime Security for Agentic Systems (Lyonnet, Clerget, Salamatian, 2026).
The code, the 50 scenario contracts, and one-command reproduction of the benchmark: github.com/edamametechnologies/agent_security
Where it was presented: PEPR IA Days 2026, Rennes, 22–24 June 2026 (France 2030 national AI research programme).
See intent divergence in the product on the EDAMAME agents page, with a short demo on a Cursor session that applies identically to Claude Code, Codex, and OpenClaw: youtu.be/zAN4u7ImWrU
Download EDAMAME Security — free for macOS, Windows, Linux, iOS, and Android; or walk it through for your own SDLC on our calendar.
Sources: F. Lyonnet, A. Clerget, K. Salamatian, “Runtime Security for Agentic Systems: A Practical Two-Plane Approach for OpenClaw-Class Agents” (HAL, 2026); PEPR IA (CEA / CNRS / Inria, France 2030). Benchmark figures are the reproducible-branch snapshot reported in the paper.
Frank Lyonnet
Share this post